As a full-fledged convert to the church of Kubernetes of the latter-day Containers, I love running applications in-cluster whenever possible. At MeanPug, we’ve been running services of all shapes and sizes on EKS for a few years now and – being a small agency – have seen an enormous boost in productivity as a result. Then along came WordPress.
A small disclaimer, I used to be a WordPress naysayer, thinking it clunky, slow, and outdated. Of late, though, I’ve had a seachange of opinion. When building content-driven sites, it deserves the crown it wears. That said, there are some thorny issues that can lead to full-blown timesucks that can lead to meltdowns, screaming, and insanity if not properly handled. Before we dive into some of these issues, let me lay out the relevant technologies in our deployment stack as a framing context:
- Docker: wordpress:5.0–php7.3–apache
- Kubernetes: v1.10.13 on EKS, Helm
- Application: WordPress Multisite
Login loop
Symptom: You login successfully and are redirected…back to the login page
When I first encountered this one, it really threw me for a loop 😑. From experience, the culprit is one of three things:
- Something in your browser cache is screwy. Try logging into an incognito window.
2. You’re sitting behind a reverse-proxy stripping out cookies. Whether this is an HAProxy load balancer or Cloudfront distribution, you’re going to need to make sure WordPress has access to the cookies it uses to track sessions. A good list of these required cookies is on this AWS blog post. For convenience, here’s the whitelist we use in our CloudFront configuration:
‘comment_author_*’,
‘comment_author_email_*’,
‘comment_author_url_*’,
‘wordpress_*’,
‘wordpress_logged_in_*’,
‘wordpress_test_cookie’,
‘wp-settings-*’
3. Your target group isn’t configured for sticky sessions. Now, in our infrastructure (Cloudfront -> R53 -> ALB -> Kubernetes), this meant enabling stickiness with this hidden setting:
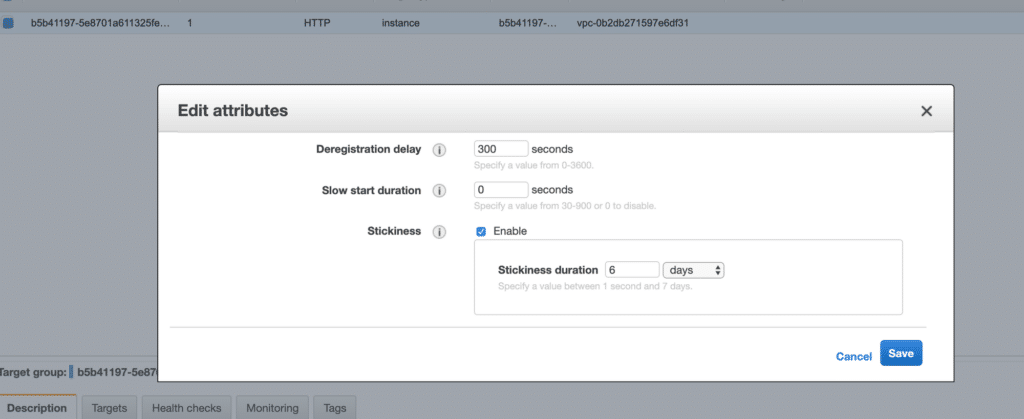
Find this by selecting target group -> Actions -> Edit Attributes
Or, if using the ALB ingress controller, the following annotation should take care of this for you:
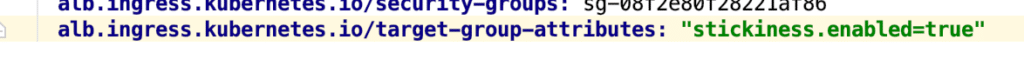
Add the following ingress annotation to add stickiness to the target group
Media Intermittently Disappears
Symptom: You upload media and it is available for a while, then at some later point 404.
Admittedly, this one isn’t too thorny, but still of the common variant of issue when configuring WordPress on Kubernetes. Invariably, it is a result of missing volume configuration. Remember that containers are ephemeral and any data stored in them will disappear on container exit, so in order to persist data between container runs a volume is required. Though configuration of Persistent Volumes and Persistent Volume Claim’s are outside the scope of this post, if your cluster is running on EKS and you followed the AWS getting started guide, you’ll have a gp2 storage class available out of the box, so for the simple case (where advanced volume configuration is unnecessary), you can get by creating a PVC directly, which will set up the underlying Persistent Volume for you. Then, it’s just a matter of mounting the volume at the appropriate mountPath in the running WordPress container. If using the standard WordPress image from Dockerhub, the relevant portions of your Deployment configuration should look something like this:
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: wp-deployment
labels:
app.kubernetes.io/name: my-wp
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: my-wp
template:
metadata:
labels:
app.kubernetes.io/name: my-wp
spec:
volumes:
- name: media
persistentVolumeClaim:
claimName: wp-media-pvc
containers:
- name: wp-container
image: wordpress:5.0-php7.3-apache
imagePullPolicy: Always
volumeMounts:
- name: media
mountPath: /var/www/html/wp-content/uploads/
....Redirect Loop
Symptom: The browser will tell you as much, and nothing more.
Maddening. Ultra maddening. Hyper maddening. Of the items listed, this is – in my humble opinion – the most bash-your-head-against-the-wall-and-beg-for-a-swift-death inducing. Luckily, once you’ve seen it once, you won’t be stumped by it again, since in every case I’ve encountered the issue boils down to a protocol mismatch between WordPress and a reverse proxy. This is much easier explained via example.
The first variation of this occurs when forwarding a request using a different protocol then originally transmitted. For instance, assume you have your site, MeanPugMugs.com, set up in WordPress with a Site URL
of https://MeanPugMugs.com, you have your reverse proxy configured to accept requests over HTTPS at https://MeanPugMugs.com, but it is configured to forward requests over HTTP to the upstream. With this configuration, even if one were to visit https://MeanPugMugs.com, because the load balancer is forwarding the request over HTTP WordPress will try to upgrade the request to HTTPS, returning a redirect to https://MeanPugMugs.com, which will then follow the same route as before, leading to a circularity.
The other variation occurs when launching your site over HTTP but upgrading requests at the load balancer level. For example. say you relaunch MeanPugMugs.com over HTTP. Your Site URL , then, would be http://MeanPugMugs.com. Our load balancer, meanwhile, is configured to redirect requests to HTTP -> HTTPS. Now, when a request comes through at http://MeanPugMugs.com, it is upgraded at the load balancer level to HTTPS via redirect to https://MeanPugMugs.com. This upgraded request is then handled by the load balancer and forwarded on to the upstream. However, the upstream is unable to handle HTTPS and downgrades to HTTP via a redirect to http://MeanPugMugs.com. Enter the dreaded circularity. The easiest solution here is simply specifying the same Site URL protocol at the load balancer and WordPress levels.
Wrapping Up
Of course, my hope is you never run into these issues in the first place. But, if you do, the goal is to guide you away from the event horizon of timesuck, towards the pearly gates of well-behaved WordPress nirvana. In a future post, we’ll dive into deploying WordPress Multisite on Kubernetes and the unique set of trials and tribulations that heralds.






